Abstract
Designing complex 3D scenes has been a tedious, manual process requiring domain expertise. Emerging text-to-3D generative models show great promise for making this task more intuitive, but existing approaches are limited to object-level generation. We introduce locally conditioned diffusion as an approach to compositional scene diffusion, providing control over semantic parts using text prompts and bounding boxes while ensuring seamless transitions between these parts. We demonstrate a score distillation sampling--based text-to-3D synthesis pipeline that enables compositional 3D scene generation at a higher fidelity than relevant baselines.
Method
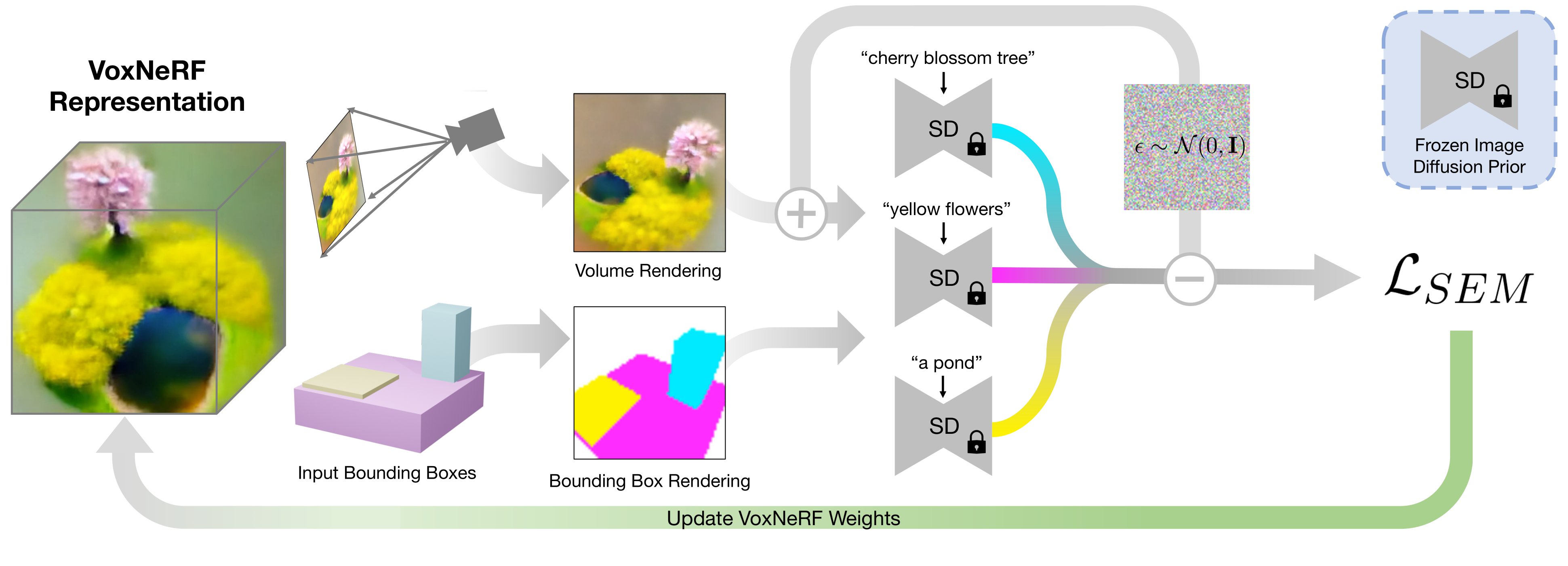
Overview of our method. We generate text-to-3D content using a score distillation sampling--based pipeline. A latent diffusion prior is used to optimize a Voxel NeRF representation of the 3D scene. The latent diffusion prior is conditioned on a bounding box rendering of the scene, where a noise estimation on the image is formed for every input text prompt, and denoising steps are applied based on the segmentation mask provided by the bounding box rendering.
Gallery
BibTeX
@article{Po2023Compositional3S,
title={Compositional 3D Scene Generation using Locally Conditioned Diffusion},
author={Ryan Po and Gordon Wetzstein},
journal={ArXiv},
year={2023},
volume={abs/2303.12218},
url={https://api.semanticscholar.org/CorpusID:257663283}
}