Abstract

Customization techniques for text-to-image models have paved the way for a wide range of previously unattainable applications, enabling the generation of specific concepts across diverse contexts and styles. While existing methods facilitate high-fidelity customization for individual concepts or a limited, pre-defined set of them, they fall short of achieving scalability, where a single model can seamlessly render countless concepts. In this paper, we address a new problem called Modular Customization, with the goal of efficiently merging customized models that were fine-tuned independently for individual concepts. This allows the merged model to jointly synthesize concepts in one image without compromising fidelity or incurring any additional computational costs.
To address this problem, we introduce Orthogonal Adaptation, a method designed to encourage the customized models, which do not have access to each other during fine-tuning, to have orthogonal residual weights. This ensures that during inference time, the customized models can be summed with minimal interference.
Multi-concept Results

Our method enables efficient merging of individually fine-tuned concepts for modular, efficient multi-concept customization of text-to-image diffusion models. Each concept shown above was fine-tuned individually using orthogonal adaptation. Fine-tuned weight residuals are then merged via summation, enabling multi-concept generation.
Problem: LoRA Crosstalk

LoRAs fine-tuned under conventional methods interfere with one another when combined naively, this effect is most noticeable when LoRA weights are similar. We refer to this effect as "crosstalk". The effects of crosstalk lead to loss of identity for customized concepts as observed on the results to the right. The goal of our method is to modify the fine-tuning regime such that resulting LoRAs have minimal crosstalk. A key observation from our experiments is that crosstalk is minimized when LoRA weights are orthogonal to each other. Measuring crosstalk through the norm of the product between two LoRA weights, our method results in lower crosstalk between independently trained LoRAs. Combined via the same method, our training regime leads to less crosstalk and therefore better identity preservation after merging.
Method
Overview of our method. (a) LoRA enables training of both low-rank decomposed matrices. (b) Orthogonal adaption constrains training only to A, leaving B fixed. (c) For two separate concepts, i and j, an orthogonality constraint is imposed between B_i and B_j. (d) When concepts i and j are trained independently, approximate orthogonality between B_i and B_j can be achieved by sampling random columns from a shared orthogonal matrix. (e) Without the orthogonality constraint, correlated concepts suffer from "crosstalk" when merged; with the orthogonality constraint, orthogonal concepts preserve their identities after merging.
Results

Orthogonal adaptation out-performs state-of-the-art baselines for multi-concept generations. While other methods suffer from identity loss due to crosstalk between individually trained LoRAs, models fine-tuned using orthogonal adaptation results in lower crosstalk, leading to better preservation of individual subject identities in the merged model.
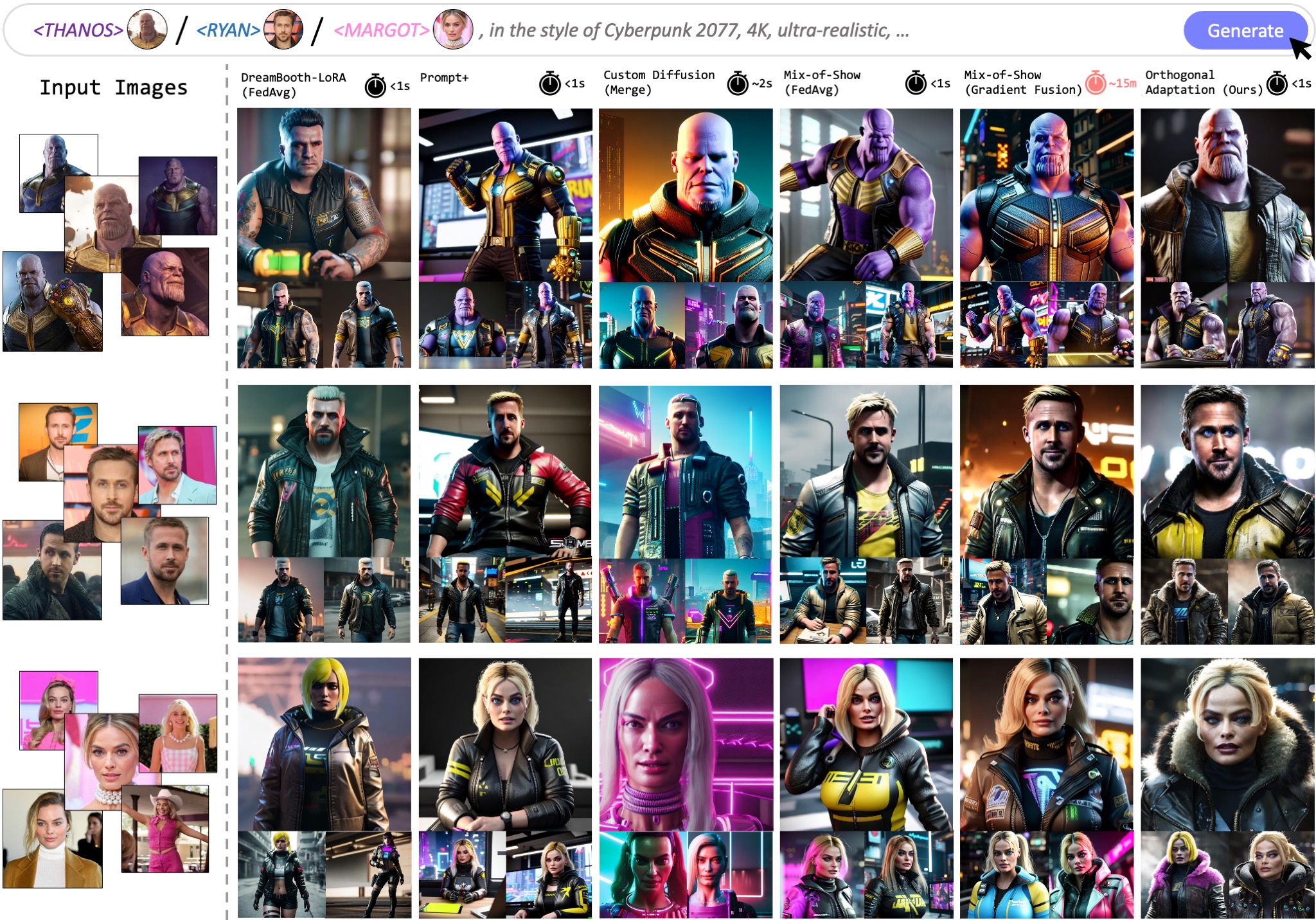
Our method outperforms competing baselines in identity preservation, while keeping merging costs low. Methods with competing levels of quality (e.g. Mix-of-Show w/ Gradient Fusion) requires an additional optimization-based merging procedure. A key contribution of our method is that LoRAs trained using orthogonal adaptation can be mergeed via naive summation while experiencing minimal subject identity loss.